max planck institut
informatik
informatik

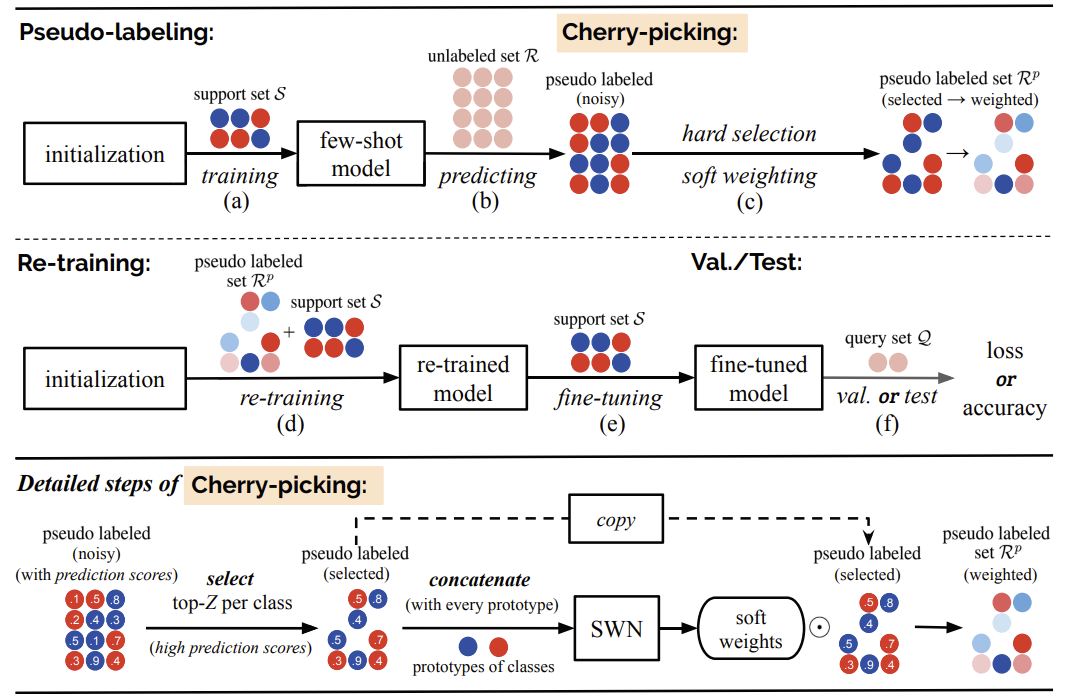
Fig 1. The pipeline of the proposed LST method on a single (2-class, 3-shot) task.
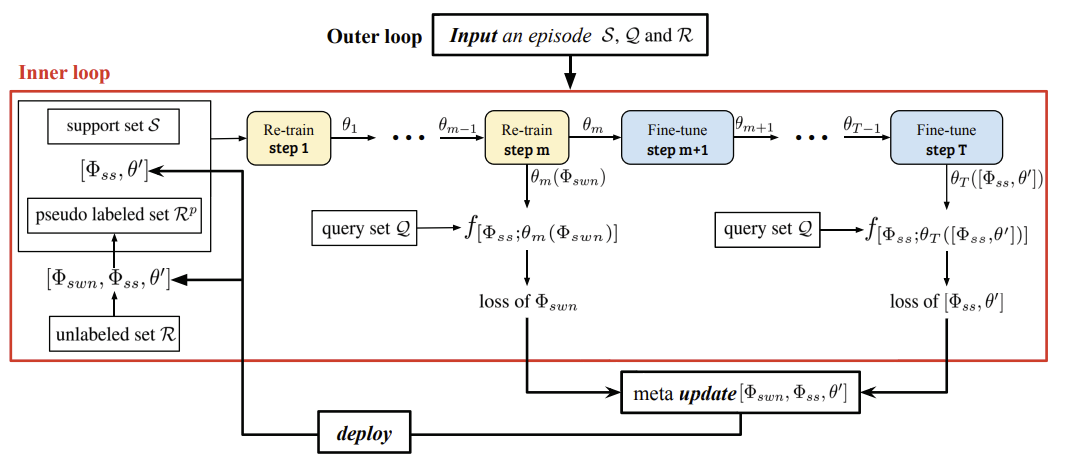
Fig 2. Outer-loop and inner-loop training procedures in our LST method. The inner loop in the red box contains the m steps of re-training and T − m steps of fine-tuning. In recursive training, the fine-tuned θT replaces the initial MTL learned θT for the pseudo-labeling at the next stage.
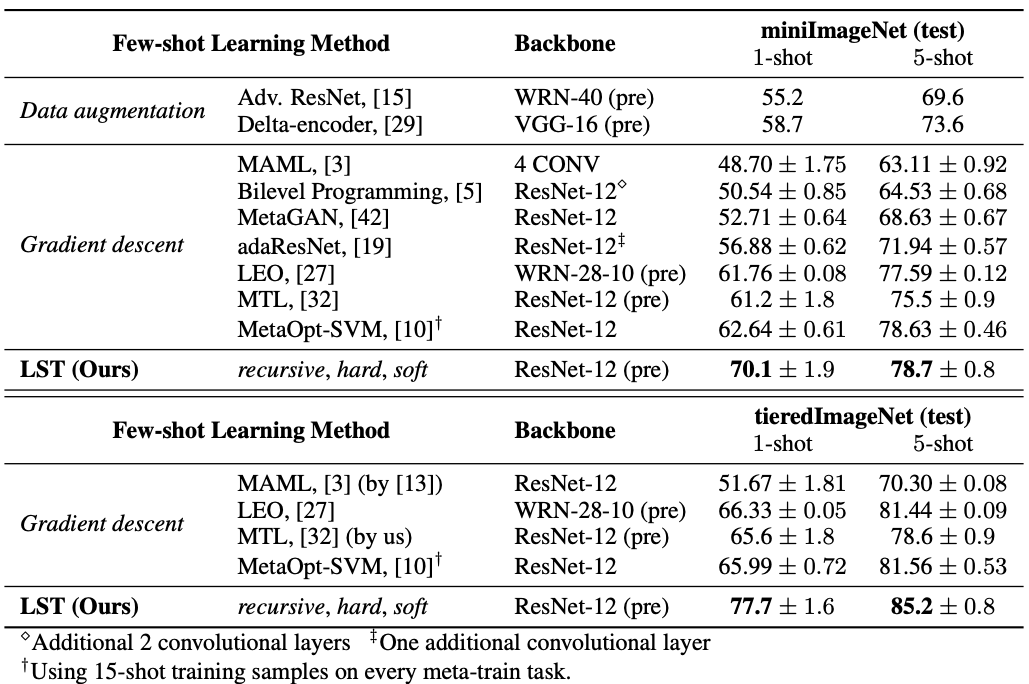
Table 1. The 5-way, 1-shot and 5-shot classification accuracy (%) on miniImageNet and tieredImageNet datasets.
Please cite our paper if it is helpful to your work:
@inproceedings{Li2019LST,
author = {Xinzhe Li and
Qianru Sun and
Yaoyao Liu and
Qin Zhou and
Shibao Zheng and
Tat{-}Seng Chua and
Bernt Schiele},
title = {Learning to Self-Train for Semi-Supervised Few-Shot Classification},
booktitle = {Advances in Neural Information Processing Systems 32: Annual Conference
on Neural Information Processing Systems 2019, NeurIPS 2019, 8-14
December 2019, Vancouver, BC, Canada},
pages = {10276--10286},
year = {2019}
}
Copyright © 2019 Max Planck Institute for Informatics |