max planck institut
informatik
informatik

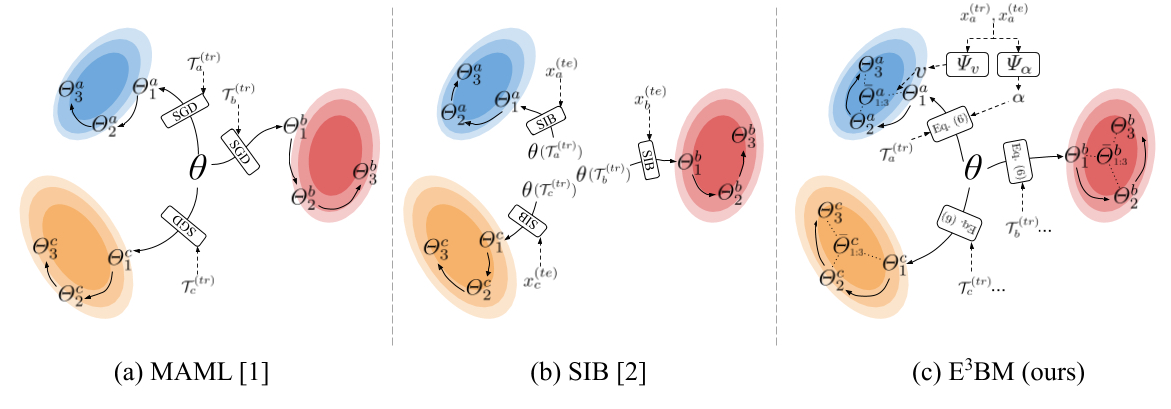
Fig 1. Conceptual illustrations of the model adaptation on the blue, red and yellow tasks. (a) MAML is the classical inductive method that meta-learns a network initialization θ that is used to learn a single base-learner on each task. (b) SIB is a transductive method that formulates a variational posterior as a function of both labeled training data T(tr) and unlabeled test data x(te). It also uses a single base-learner and optimizes the learner by running several synthetic gradient steps on x(te). (c) Our E3BM is a generic method that learns to combine the epoch-wise base-learners, and to generate task-specific learningcrates α and combination weights v that encourage robust adaptation.
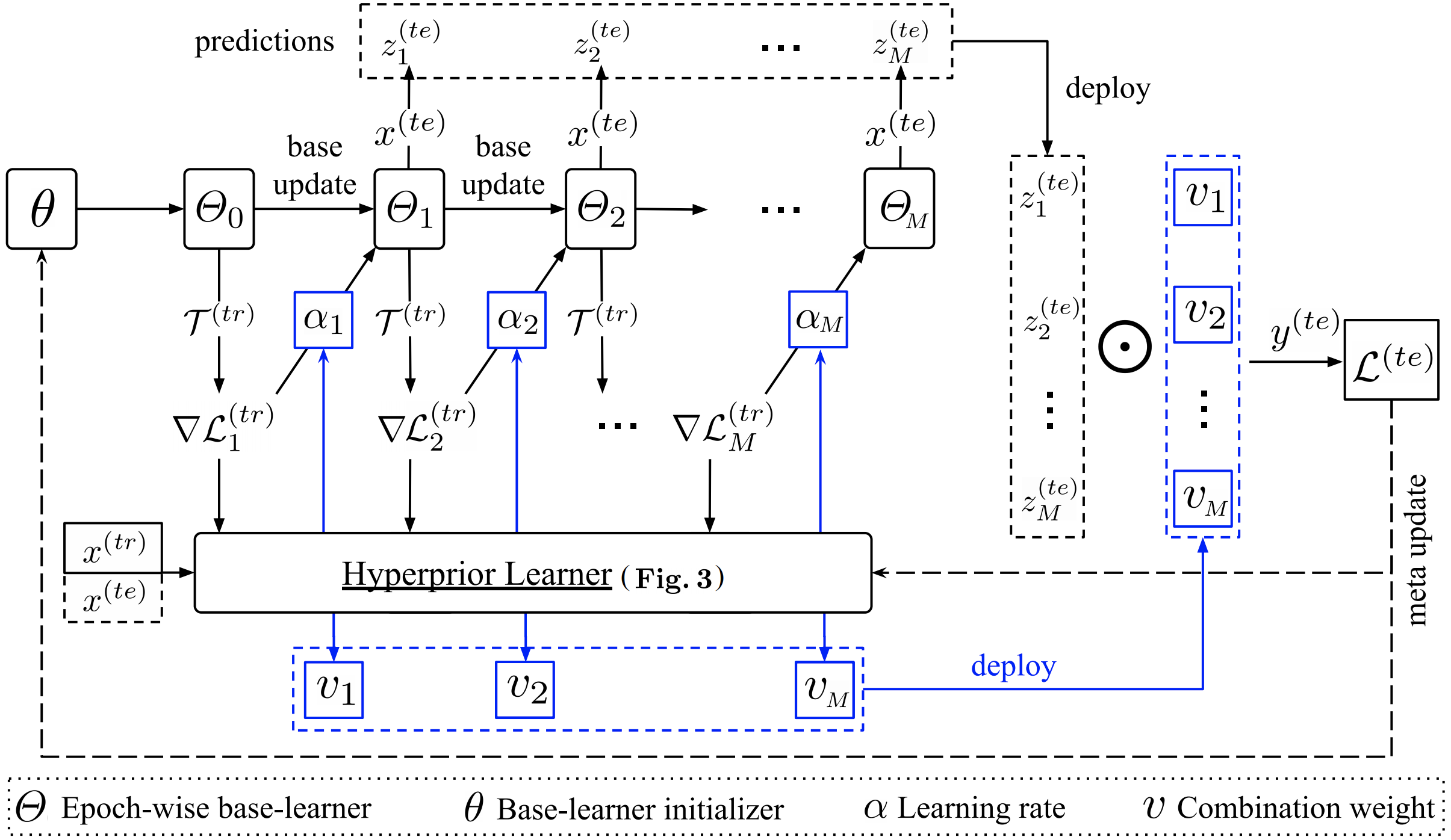
Fig 2. The computing flow of the proposed E3BM approach in one meta-training episode. For the meta-test task, the computation will be ended with predictions. Hyperlearner predicts task-specific hyperparameters, i.e., learning rates and multi-model combination weights. When its input contains x(te), it is transductive, otherwise inductive. Its detailed architecture is given in Fig. 3.
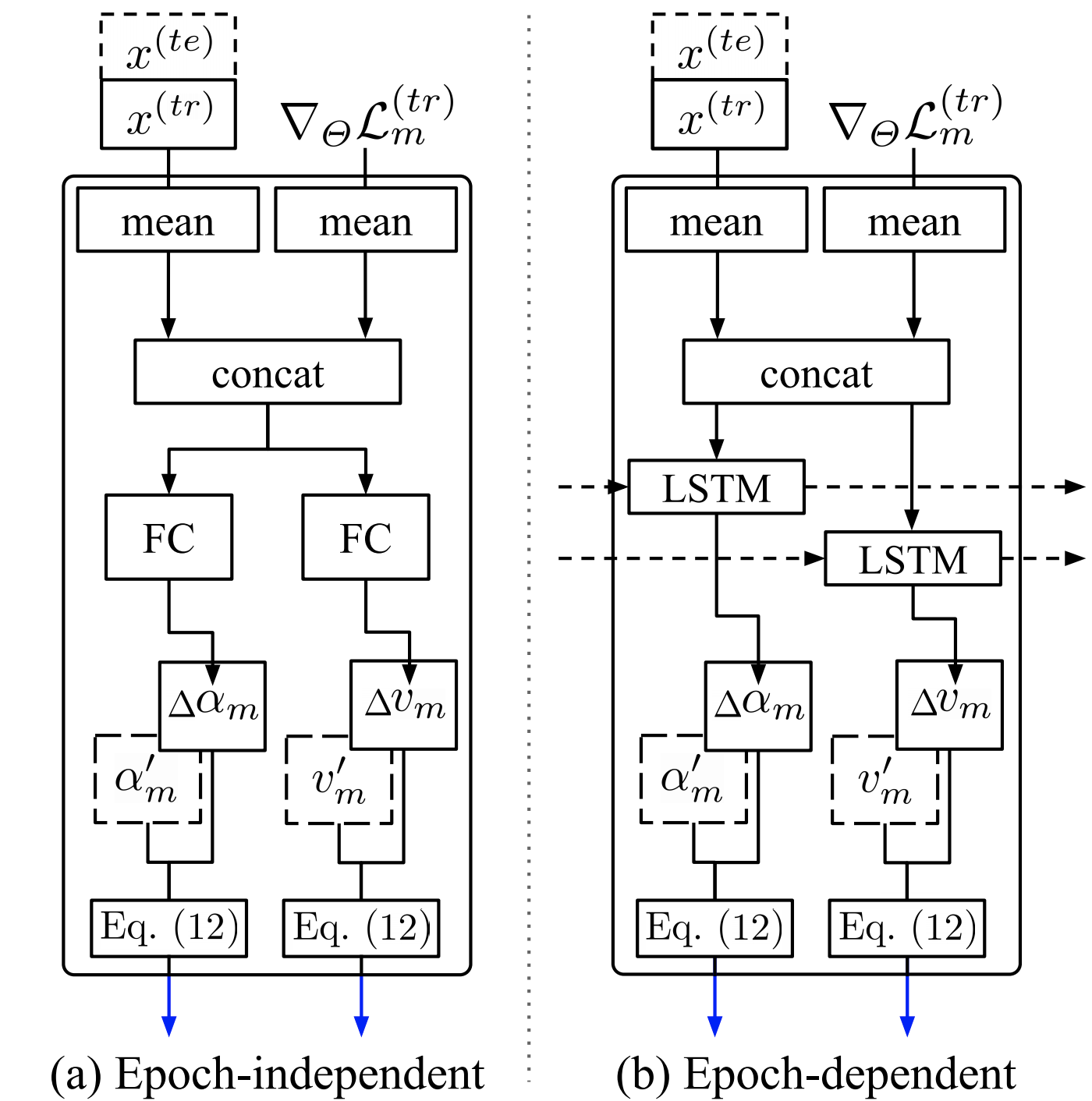
Fig 3. Two options of hyperprior learner at the m-th base update epoch. In terms of the mapping function, we deploy either FC layers to build epoch-independent hyperprior learners, or LSTM to build an epoch-dependent learner. Values in dashed box were learned from previous tasks.
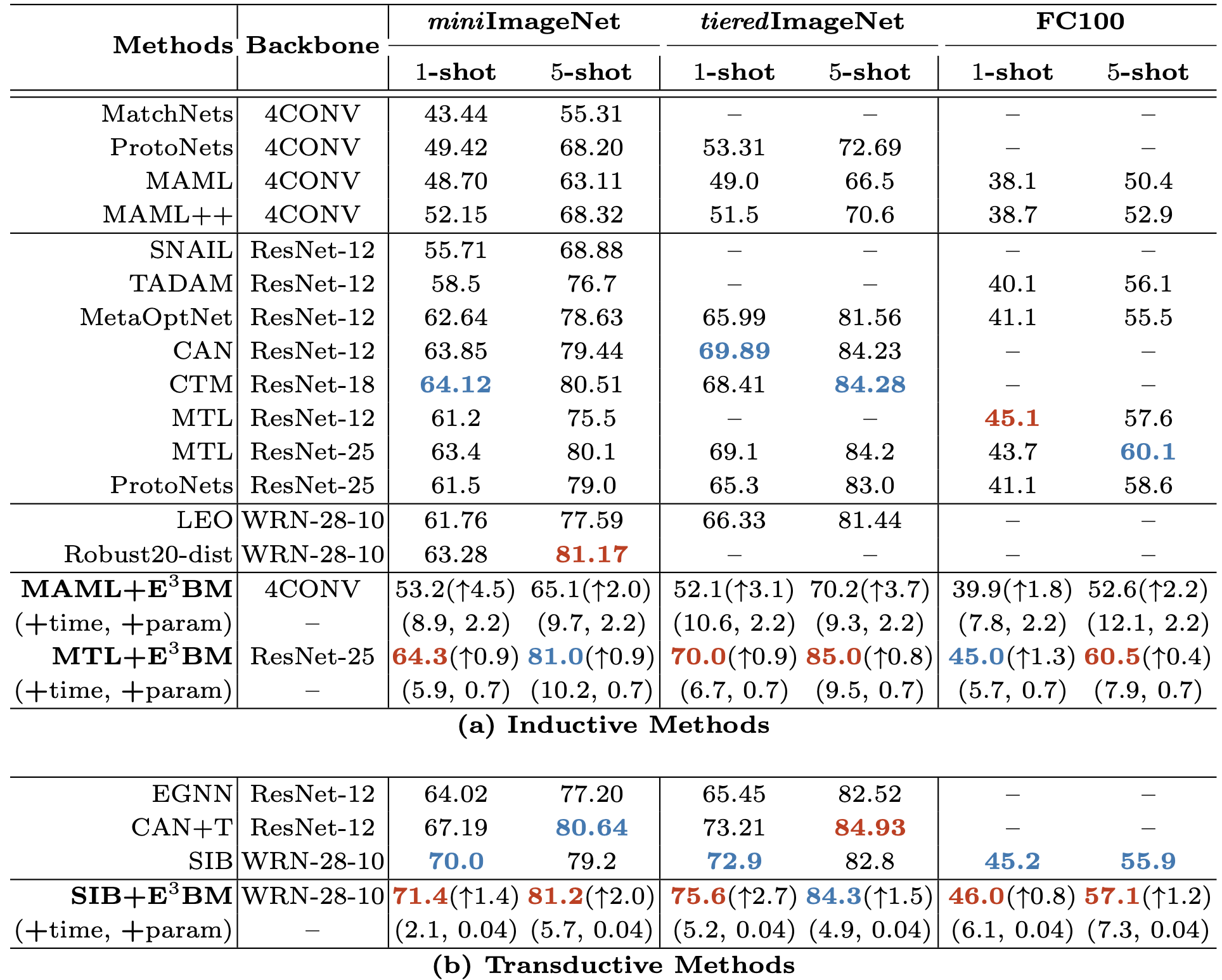
Table 1. The 5-class few-shot classification accuracies (%) on miniImageNet, tieredImageNet, and FC100. “(+time, +param)” denote the additional computational time (%) and parameter size (%), respectively, when plugging-in E3BM to baselines (MAML, MTL and SIB).
Please cite our paper if it is helpful to your work:
@inproceedings{Liu2020E3BM,
author = {Liu, Yaoyao and
Schiele, Bernt and
Sun, Qianru},
title = {An Ensemble of Epoch-wise Empirical Bayes for Few-shot Learning},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020}
}
[1] Finn, Chelsea, Pieter Abbeel, and Sergey Levine. "Model-agnostic meta-learning for fast adaptation of deep networks." ICML 2017.
[2] Hu, Shell Xu, et al. "Empirical Bayes Transductive Meta-Learning with Synthetic Gradients." ICLR 2020.
Copyright © 2020 Max Planck Institute for Informatics |