max planck institut
informatik
informatik

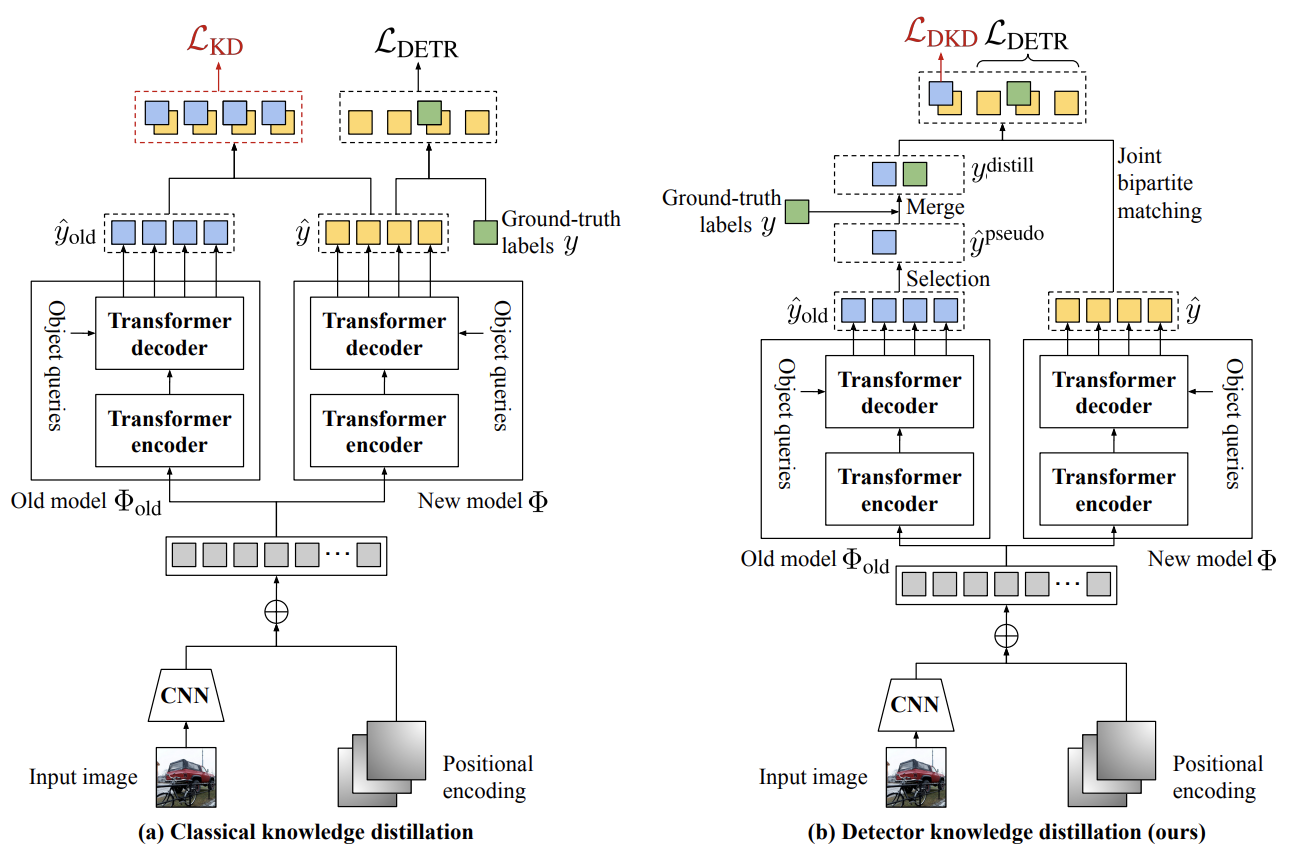
Fig 1. (a) Classical knowledge distillation. There are two issues when directly applying KD to the transformer-based detectors. (i) Transformer-based detectors work by testing a large number of object hypotheses in parallel. Because the number of hypotheses is much larger than the typical number of objects in an image, most of them are negative, resulting in an unbalanced KD loss. (ii) Because both old and new object categories can co-exist in any given training image, the KD loss and regular training objective can provide contradictory evidence. (b) Detector knowledge distillation (ours). We select the most confident foreground predictions from the old model and use them as pseudo labels. We purposefully ignore background predictions because they are imbalanced and they can contradict the labels of the new classes available in the current phase. Then, we merge the pseudo labels for the old categories with the ground-truth labels for the new categories and use bipartite matching to train the model on the joint labels. This inherits the good properties of the original formulation such as ensuring one-to-one matching between labels and hypotheses and avoiding duplicate detections.
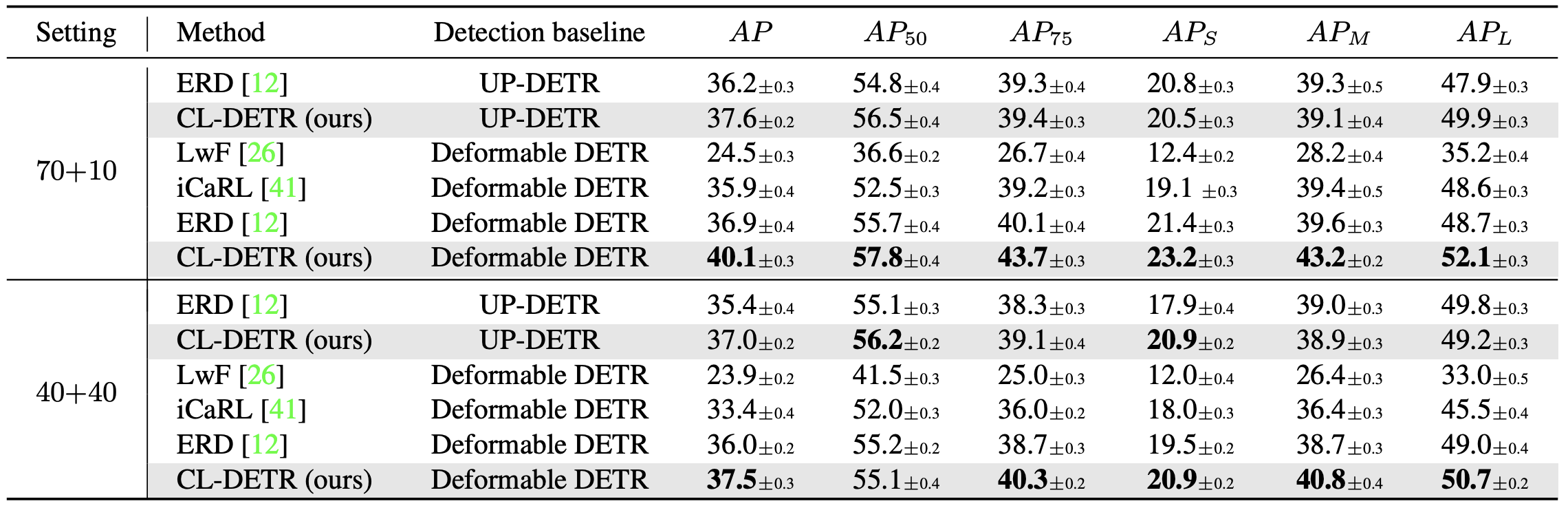
Table 1. IOD results (%) on COCO 2017. In the A + B setup, in the first phase, we observe a fraction A/(A+B) of the training samples with A categories annotated. Then, in the second phase, we observe the remaining B A+B of the training samples, where B new categories are annotated. We test settings A + B = 40 + 40 and 70 + 10. Exemplar replay is applied for all methods except for LwF. We run experiments for three different categories and data orders and report the average AP with 95% confidence interval.
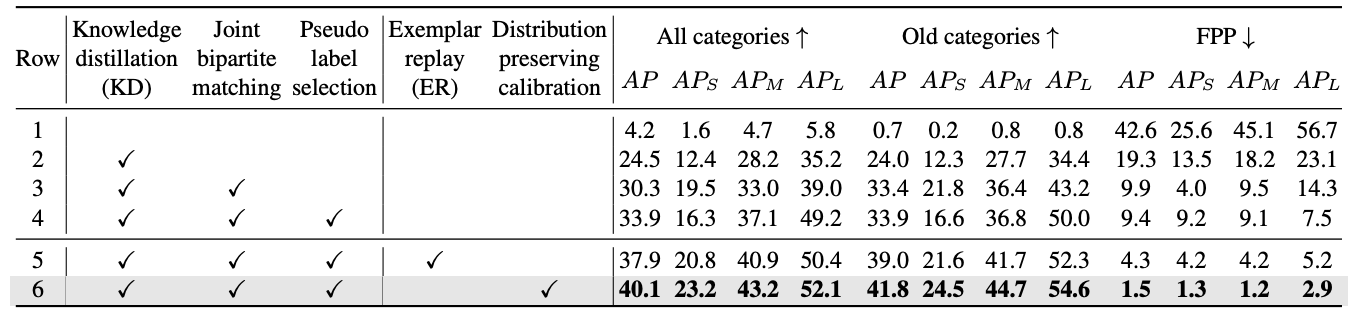
Table 2. Ablation results (%) for KD and ER, using Deformable DETR on COCO 2017 in the 70+ 10 setting. “All categories” (higher is better) denote the results of the last phase model on 80 categories. “Old categories” (higher is better) denote the results of the last phase model on 70 categories observed in the first phase. “Forgetting percentage points (FPP)” (lower is better) show the difference between the AP of the first-phase model and the last-phase model on 70 categories observed in the first phase. The baseline (row 1) is finetuning the model without IOD techniques. Our method (CL-DETR) is shown in row 6.
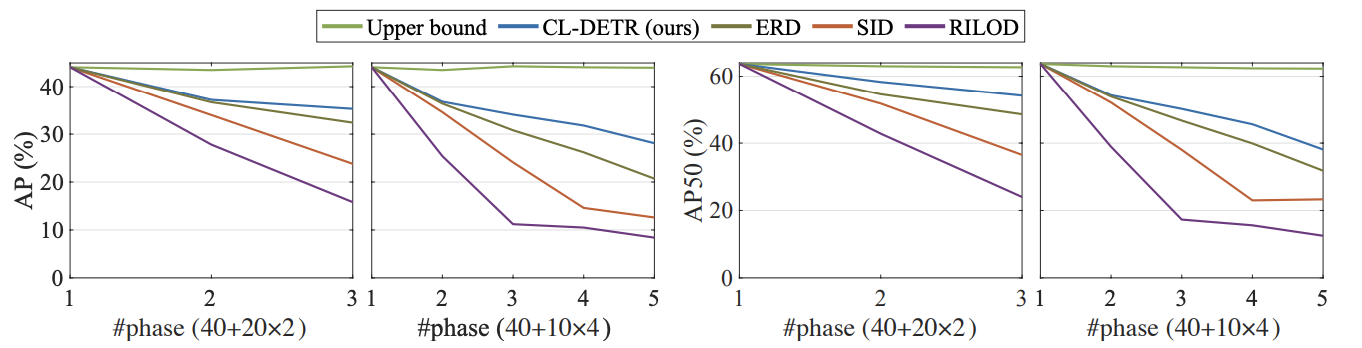
Figure 2. IOD results (AP/AP50, %) on COCO 2017 in the 40+20×2 and 40+10×4 settings. Our method is based on Deformable DETR. Comparing methods: Upper Bound (the results of joint training with all previous data accessible in each phase), ERD, SID, and RILOD.
Please cite our paper if it is helpful to your work:
@inproceedings{Liu2023Continual,
author = {Yaoyao Liu and
Bernt Schiele and
Andrea Vedaldi and
Christian Rupprecht},
title = {Continual Detection Transformer for Incremental Object Detection},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
pages = {23799-23808}
}
Copyright © 2023 Max Planck Institute for Informatics |